
Autoencoder
mse autoencoder
# 데이터 불러오기
from tensorflow.keras.datasets import mnist
# unsupervised learning
(X_train,_), (X_test,_) = mnist.load_data()
X_train = X_train/255.
X_test = X_test/255.
# 데이터 모델 만들기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv2D
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(28,28,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(28))
model.summary()
'''
Model: "sequential_25"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_105 (Dense) (None, 28, 64) 1856
_________________________________________________________________
dense_106 (Dense) (None, 28, 32) 2080
_________________________________________________________________
dense_107 (Dense) (None, 28, 8) 264
_________________________________________________________________
dense_108 (Dense) (None, 28, 32) 288
_________________________________________________________________
dense_109 (Dense) (None, 28, 64) 2112
_________________________________________________________________
dense_110 (Dense) (None, 28, 28) 1820
=================================================================
Total params: 8,420
Trainable params: 8,420
Non-trainable params: 0
_________________________________________________________________
'''
model.compile(loss='mse', metrics = ['mse'], optimizer= 'adam')
model.fit(X_train,X_train,epochs=3)
'''
Train on 60000 samples
Epoch 1/3
60000/60000 [==============================] - 9s 157us/sample - loss: 0.0077 - mse: 0.0077
Epoch 2/3
60000/60000 [==============================] - 9s 151us/sample - loss: 0.0027 - mse: 0.0027
Epoch 3/3
60000/60000 [==============================] - 10s 174us/sample - loss: 0.0023 - mse: 0.0023
'''
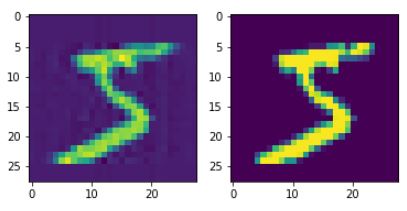
- autoencoder한 값 비교해보기
a = model.predict(X_train)[0]
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1,2)
axes[0].imshow(a)
axes[1].imshow(X_train[0])
binary_crossentropy로 autoencoder
model = Sequential()
model.add(Dense(64, activation='relu', input_shape=(28*28,)))
model.add(Dense(32, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(64, activation='relu'))
model.add(Dense(28*28, activation='sigmoid'))
model.summary()
'''
Model: "sequential_7"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_42 (Dense) (None, 64) 50240
_________________________________________________________________
dense_43 (Dense) (None, 32) 2080
_________________________________________________________________
dense_44 (Dense) (None, 8) 264
_________________________________________________________________
dense_45 (Dense) (None, 32) 288
_________________________________________________________________
dense_46 (Dense) (None, 64) 2112
_________________________________________________________________
dense_47 (Dense) (None, 784) 50960
=================================================================
Total params: 105,944
Trainable params: 105,944
Non-trainable params: 0
_________________________________________________________________
'''
model.compile(loss='binary_crossentropy', optimizer= 'adam')
model.fit(X_test.reshape(-1,28*28), X_test.reshape(-1,28*28), epochs=10)
'''
Train on 10000 samples
Epoch 1/10
10000/10000 [==============================] - 2s 184us/sample - loss: 0.2877
Epoch 2/10
10000/10000 [==============================] - 1s 114us/sample - loss: 0.2203
Epoch 3/10
10000/10000 [==============================] - 1s 138us/sample - loss: 0.1823
Epoch 4/10
10000/10000 [==============================] - 1s 120us/sample - loss: 0.1705
Epoch 5/10
10000/10000 [==============================] - 1s 114us/sample - loss: 0.1638
Epoch 6/10
10000/10000 [==============================] - 1s 131us/sample - loss: 0.1595
Epoch 7/10
10000/10000 [==============================] - 1s 130us/sample - loss: 0.1568
Epoch 8/10
10000/10000 [==============================] - 1s 144us/sample - loss: 0.1547
Epoch 9/10
10000/10000 [==============================] - 2s 156us/sample - loss: 0.1530
Epoch 10/10
10000/10000 [==============================] - 1s 122us/sample - loss: 0.1515
<tensorflow.python.keras.callbacks.History at 0x1d092704c18>
'''
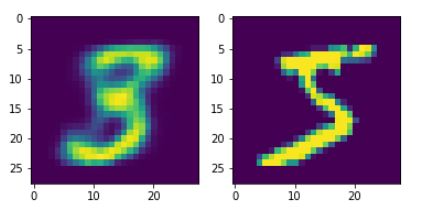
- 데이터 확인
a = model.predict(X_train.reshape(-1,28*28))[0]
fig, axes = plt.subplots(1,2)
axes[0].imshow(a.reshape(28,28))
axes[1].imshow(X_train[0])
Encoder / decoder
layer1 = Dense(64, activation = 'relu', input_shape = (28*28,))
layer2 = Dense(32, activation = 'relu')
layer3 = Dense(8, activation = 'relu')
layer4 = Dense(28*28)
encoder = Sequential([layer1,layer2,layer3, layer4])
layer5 = Dense(32, activation='relu', input_shape=(8,))
layer6 = Dense(64, activation='relu')
layer7 = Dense(28*28, activation = 'sigmoid')
decoder = Sequential([layer5, layer6, layer7])
encoder.compile(loss= 'mse', optimizer= 'adam')
encoder.output_shape
# (None, 784)
encoder.fit(X_train.reshape(-1,28*28),X_train.reshape(60000,28*28),epochs=2)
'''
Train on 60000 samples
Epoch 1/2
60000/60000 [==============================] - 5s 84us/sample - loss: 0.0493
Epoch 2/2
60000/60000 [==============================] - 5s 75us/sample - loss: 0.0452
<tensorflow.python.keras.callbacks.History at 0x1d09aac4208>
'''
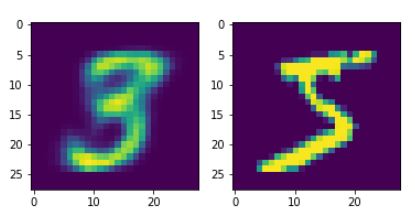
- encoder 데이터 확인
a = ende.predict(X_train.reshape(-1,28*28))[0]
fig, axes = plt.subplots(1,2)
axes[0].imshow(a.reshape(28,28))
axes[1].imshow(X_train[0])
- encoder + decoder
ende = Sequential([encoder,decoder])
ende.summary()
'''
Model: "sequential_22"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_20 (Sequential) (None, 8) 52584
_________________________________________________________________
sequential_21 (Sequential) (None, 784) 53360
=================================================================
Total params: 105,944
Trainable params: 105,944
Non-trainable params: 0
_________________________________________________________________
'''
ende.compile(loss='binary_crossentropy', optimizer= 'adam')
ende.fit(X_train.reshape(-1,28*28),X_train.reshape(-1,28*28),epochs=2)
'''
Train on 60000 samples
Epoch 1/2
60000/60000 [==============================] - 7s 121us/sample - loss: 0.1896
Epoch 2/2
60000/60000 [==============================] - 6s 107us/sample - loss: 0.1549
<tensorflow.python.keras.callbacks.History at 0x1d09a26c550>
'''
- encoder + decoder 데이터 확인
a = ende.predict(X_train.reshape(-1,28*28))[0]
fig, axes = plt.subplots(1,2)
axes[0].imshow(a.reshape(28,28))
axes[1].imshow(X_train[0])

Building Autoencoders in keras
Deep autoencoder
- activity_regularizer=regularizers.l1(10e-5) (no free lunch)
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras import regularizers
input_img = Input(shape=(784,))
encoded = Dense(32, activation='relu',
activity_regularizer=regularizers.l1(10e-5))(input_img)
# kernel_regularizer, bias_regularizer 은 자기 자신값을 변형시켜버리기 때문에 쓰지 않는다.
# mse는 값이 너무 커진다. mse로 풀어도 상관없다.
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
encoder = Model(input_img, encoded)
encoded_output = Input(shape=(32,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(encoded_output, decoder_layer(encoded_output))
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train/255.
x_test = x_test/255.
x_train = x_train.reshape(-1, 28*28)
x_test = x_test.reshape(-1, 28*28)
autoencoder.fit(x_train, x_train,
epochs=10,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
'''
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
60000/60000 [==============================] - 8s 140us/sample - loss: 0.6967 - val_loss: 0.6967
Epoch 2/10
60000/60000 [==============================] - 5s 83us/sample - loss: 0.6965 - val_loss: 0.6965
Epoch 3/10
60000/60000 [==============================] - 5s 80us/sample - loss: 0.6963 - val_loss: 0.6962
Epoch 4/10
60000/60000 [==============================] - 5s 78us/sample - loss: 0.6960 - val_loss: 0.6960
Epoch 5/10
60000/60000 [==============================] - 5s 84us/sample - loss: 0.6958 - val_loss: 0.6958
Epoch 6/10
60000/60000 [==============================] - 5s 86us/sample - loss: 0.6956 - val_loss: 0.6956
Epoch 7/10
60000/60000 [==============================] - 5s 88us/sample - loss: 0.6954 - val_loss: 0.6954
Epoch 8/10
60000/60000 [==============================] - 5s 91us/sample - loss: 0.6952 - val_loss: 0.6952
Epoch 9/10
60000/60000 [==============================] - 5s 78us/sample - loss: 0.6950 - val_loss: 0.6950
Epoch 10/10
60000/60000 [==============================] - 5s 82us/sample - loss: 0.6948 - val_loss: 0.6948
<tensorflow.python.keras.callbacks.History at 0x1d0d206ae80>
'''
- Deep Autoencoder
sparse 방식
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
encoded = Dense(64, activation='relu')(encoded)
encoded = Dense(32, activation='relu')(encoded)
decoded = Dense(64, activation='relu')(encoded)
decoded = Dense(128, activation='relu')(decoded)
decoded = Dense(784, activation='sigmoid')(decoded)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
autoencoder.fit(x_train, x_train,
epochs=5,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
'''
Train on 60000 samples, validate on 10000 samples
Epoch 1/5
60000/60000 [==============================] - 6s 92us/sample - loss: 0.6942 - val_loss: 0.6941
Epoch 2/5
60000/60000 [==============================] - 4s 61us/sample - loss: 0.6941 - val_loss: 0.6941
Epoch 3/5
60000/60000 [==============================] - 4s 63us/sample - loss: 0.6940 - val_loss: 0.6940
Epoch 4/5
60000/60000 [==============================] - 4s 61us/sample - loss: 0.6939 - val_loss: 0.6939
Epoch 5/5
60000/60000 [==============================] - 4s 59us/sample - loss: 0.6938 - val_loss: 0.6938
<tensorflow.python.keras.callbacks.History at 0x1d0ce1e0b70>
'''
Convolutional autoencoder
- fully connected 보다 convolution한 autoencoder가 성능이 더 좋다.
stack 방식
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, UpSampling2D
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
import numpy as np
(x_train,_), (x_test,_) = mnist.load_data()
x_train = x_train/255.
x_test = x_test/255.
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
input_img = Input(shape=(28,28,1))
x = Conv2D(16,(3,3), activation='relu', padding ='same')(input_img)
x = MaxPooling2D((2,2), padding='same')(x)
x = Conv2D(8, (3,3), activation='relu', padding='same')(x)
x = MaxPooling2D((2,2), padding='same')(x)
x = Conv2D(8, (3,3), activation='relu', padding='same')(x)
encoded = MaxPooling2D((2,2), padding='same')(x)
x = Conv2D(8, (3,3), activation='relu', padding='same')(x)
x = UpSampling2D((2,2))(x)
x = Conv2D(8, (3,3), activation='relu', padding='same')(x)
x = UpSampling2D((2,2))(x)
# padding: same - > valid
x = Conv2D(16, (3,3), activation = 'relu', padding = 'same')(x)
x = UpSampling2D((2,2))(x)
# 마지막에 Conv2D 1로 해줘야한다.
decoded = Conv2D(1, (3,3), activation='sigmoid', padding = 'same')(x)
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer='adadelta', loss='binary_crossentropy')
임의로 output 2개, loss 2개인 모델 만들기
- 동료분 코드 참고
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
inp = Input(shape=(28,28))
layer1 = Dense(2, kernel_initializer='ones')(inp)
layer2 = Dense(2, kernel_initializer='ones')(inp)
layer1_1 = Dense(28)(layer1)
layer2_1 = Dense(28)(layer2)
test_model = Model(inp, [layer1_1,layer2_1])
test_model.summary()
'''
Model: "model_17"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_15 (InputLayer) [(None, 28, 28)] 0
__________________________________________________________________________________________________
dense_37 (Dense) (None, 28, 2) 58 input_15[0][0]
__________________________________________________________________________________________________
dense_38 (Dense) (None, 28, 2) 58 input_15[0][0]
__________________________________________________________________________________________________
dense_39 (Dense) (None, 28, 28) 84 dense_37[0][0]
__________________________________________________________________________________________________
dense_40 (Dense) (None, 28, 28) 84 dense_38[0][0]
==================================================================================================
Total params: 284
Trainable params: 284
Non-trainable params: 0
__________________________________________________________________________________________________
'''
- outputs 2개
test_model.output
'''
[<tf.Tensor 'dense_39/Identity:0' shape=(None, 28, 28) dtype=float32>,
<tf.Tensor 'dense_40/Identity:0' shape=(None, 28, 28) dtype=float32>]
'''
- 임의로 만든 loss function
def custom_loss(x, pred):
return (x-pred)**2
- compile(loss 2개)
test_model.compile(loss=['binary_crossentropy', custom_loss], optimizer='adam')
- 데이터 만들기
(x_train, _), (x_test, _) = mnist.load_data()
x_train = x_train.astype('float32')/255.
x_test = x_test.astype('float32')/255.
- target을 2개 넣는다.
ht = test_model.fit(x_train, [x_train,x_train], epochs =5, batch_size=10)
'''
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 13s 210us/sample - loss: 1.2913 - dense_39_loss: 1.1831 - dense_40_loss: 0.1081
Epoch 2/5
60000/60000 [==============================] - 12s 203us/sample - loss: 1.0790 - dense_39_loss: 1.0399 - dense_40_loss: 0.0392
Epoch 3/5
60000/60000 [==============================] - 12s 206us/sample - loss: 1.0745 - dense_39_loss: 1.0355 - dense_40_loss: 0.0390
Epoch 4/5
60000/60000 [==============================] - 11s 187us/sample - loss: 1.0735 - dense_39_loss: 1.0346 - dense_40_loss: 0.0390
Epoch 5/5
60000/60000 [==============================] - 11s 185us/sample - loss: 1.0719 - dense_39_loss: 1.0329 - dense_40_loss: 0.0390
'''
- 기본 loss가 1개 나오고,
- 지정한 loss가 각각 1개씩 나온다.
ht.history
'''
{'loss': [1.2912812048494815,
1.0790308263997237,
1.0744832996030649,
1.0735437232951324,
1.071898257335027],
'dense_39_loss': [1.1831374, 1.0398649, 1.0354929, 1.034579, 1.0329417],
'dense_40_loss': [0.10814286,
0.039164938,
0.03898862,
0.038964037,
0.038956292]}
'''
- loss는 각각 loss에 대한 합인듯) - 근사값
for lt, l1, l2 in zip(*ht.history.values()):
print(f"{lt} (lt) = {l1+l2} (l1+l2)")
print(lt == l1+l2)
'''
1.2912812048494815 (lt) = 1.2912802696228027 (l1+l2)
False
1.0790308263997237 (lt) = 1.0790297985076904 (l1+l2)
False
1.0744832996030649 (lt) = 1.07448148727417 (l1+l2)
False
1.0735437232951324 (lt) = 1.0735430717468262 (l1+l2)
False
1.071898257335027 (lt) = 1.0718979835510254 (l1+l2)
False
'''
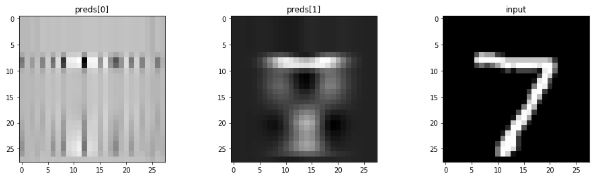
- predict
- input 1개에 대해서 output 2개가 나온다.
preds = test_model.predict(x_test[0][np.newaxis])
preds[0].shape, preds[1].shape
# ((1, 28, 28), (1, 28, 28))
- 각각 다른 loss function이 적용된 것 같다.
- loss function만 다르게 하고 구조는 같은데, output 2개가 많이 다르다.
- 모델을 제대로 만들면 잘 나올 것 같다.
plt.figure(figsize=(16,4))
ax1 = plt.subplot(1,3,1)
ax1.imshow(preds[0].squeeze())
ax1.set_title('preds[0]')
ax2 = plt.subplot(1,3,2)
ax2.imshow(preds[1].squeeze())
ax2.set_title('preds[1]')
ax3 = plt.subplot(1,3,3)
ax3.imshow(x_test[0])
ax3.set_title('input')
plt.show()
Comments