
본 과정은 제가 파이썬 수업을 들으면서 배운 내용을 복습하는 과정에서 적어본 것입니다.
틀린 부분이 있다면 댓글에 남겨주시면 고치도록 하겠습니다.
확실하지 않은 내용은 ‘(?)’을 함께 적었으니 그 내용을 아신다면 댓글에 남겨주시면 감사하겠습니다.
ps. 지혁아 고맙다. 공부할 겸 좀 참고할겡
- 책 추천: 손에 잡히는 파이썬, fluent 파이썬
2019년 11월 4일
1) Python
파이썬이란?
파이썬은 네덜란드 출신인 귀도 반 로섬(Guido Van Rossum)에 의해 1980년대 후기에 개념화되었고, 1991년에 파이썬 0.9.0으로 처음 출시되었습니다.
파이썬은 더블 배럴 형 샷건이라고 묘사되곤 합니다. 그 이유는 파이선2가 2000년에 출시되고나서 파이썬3이 2008년도에 나왔지만, 서로 100% 호환이 안되었기 때문입니다. 파이썬3는 유니코드 기반이라서 속도가 4-5배정도 늦었습니다. 따라서 파이썬3로 넘어가기까지 오랜 시간이 걸렸습니다. 하지만 2020년도에 파이썬2가 공식 종료된다고 합니다.
파이썬의 우아함과 간결성으로 Dropbox, Google, Quora, Mozilla 등 많은 유명한 IT 회사들이 파이썬을 사용하였습니다. 인스타그램 역시 파이썬 기반의 장고로 만들었습니다. 최고의 SNS APP이 파이썬으로 만들어진 것입니다. 프로그래밍 언어 도감에 따르면 인공지능에 관련되서 파이썬이 좋을 수 밖에 없는 몇가지 이유를 서술 했습니다.
파이썬은 배우기 쉽고, 강력한 프로그래밍 언어입니다. 효율적인 자료 구조들과 객체 지향 프로그래밍에 대해 간단하고도 효과적인 접근법을 제공합니다. 우아한 문법과 동적 타이핑(typing)은, 인터프리터 적인 특징들과 더불어, 대부분 플랫폼과 다양한 문제 영역에서 스크립트 작성과 빠른 응용 프로그램 개발에 이상적인 환경을 제공합니다.
파이썬 인터프리터와 풍부한 표준 라이브러리는 소스나 바이너리 형태로 파이썬 웹 사이트, https://www.python.org/ 에서 무료로 제공되고, 자유롭게 배포할 수 있습니다. 같은 사이트는 제삼자들이 무료로 제공하는 확장 모듈, 프로그램, 도구, 문서들의 배포판이나 링크를 포함합니다.
파이썬 인터프리터는 C 나 C++ (또는 C에서 호출 가능한 다른 언어들)로 구현된 새 함수나 자료 구조를 쉽게 추가할 수 있습니다. 파이썬은 고객화 가능한 응용 프로그램을 위한 확장 언어로도 적합합니다.
파이썬이 배우기 쉬운 이유는 문법이 35개밖에 없기 때문입니다. 또한 효율적인 자료구조를 갖고 있고, 멀티 패러다임으로 절차 지향, 객체 지향, 함수지향 프로그래밍이 모두 가능합니다. 객체 지향 프로그래밍을 쓰는 이유는 현재 나와있는 모든 프로그램 기법 중에서 유지 및 보수하는게 제일 편하기 때문입니다. 파이썬은 java로 만든 jython, c로 만든 python 등 다양한 대체, 플랫폼 특정 구현체가 있습니다.
구글이 원래는 C++, java, python을 많이 써서 귀도 반 로섬을 스카웃해 갔지만, 호환성 문제 때문에 ‘go’라는 언어를 구글이 자체적으로 만들게 되었고, 귀도 반 로섬도 dropbox로 이직을 하게 되었습니다. 그리고 최근에 귀도 반 로섬이 공식 은퇴 선언을 했다고 합니다.
파이썬 철학 및 소개
파이선은 생각을 표현해내는 도구인 동시에, 생각이 구체화되는 틀입니다. 파이썬 언어가 지향하고자 하는 철학을 아래 코딩을 통해 확인해 볼 수 있습니다.
import antigravity
import this
# PEP 20
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
아름다운 것이 보기 싫은 것보다 좋다.
명시적인 것이 암묵적인 것보다 좋다.
간단한 것이 복합적인 것보다 좋다.
복합적인 것이 복잡한 것보다 좋다.
수평한 것이 중첩된 것보다 좋다.
희소한 것이 밀집된 것보다 좋다.
가독성이 중요하다.
규칙을 무시할 만큼 특별한 경우는 없다.
하지만 실용성이 순수함보다 우선한다.
에러가 조용히 넘어가서는 안된다.
명시적으로 조용히 만든 경우는 제외한다.
모호함을 만났을 때 추측의 유혹을 거부해라.
하나의 — 가급적 딱 하나의 — 확실한 방법이 있어야 한다.
하지만 네덜란드 사람(귀도)이 아니라면 처음에는 그 방법이 명확하게 보이지 않을 수 있다.
지금 하는 것이 안하는 것보다 좋다.
하지만 안하는 것이 이따금 지금 당장 하는 것보다 좋을 때가 있다.
설명하기 어려운 구현이라면 좋은 아이디어가 아니다.
설명하기 쉬운 구현이라면 좋은 아이디어다.
네임스페이스는 아주 좋으므로 더 많이 사용하자!
Python의 특징
- Multi Paradigm
- 파이썬은 절차 지향, 객체 지향, 함수지향 패러다임을 모두 지원하고 있다.
- Glue Language
- 언어이면서 명세서인 파이썬은 순수한 프로그램 언어로서의 기능 외에도 다른 언어로 쓰인 모듈(file)들을 연결하는 풀 언어이다. 풀 언어라는 것은 다른 언어들과도 잘 호환된다는 것이다. C언어로 구현한 CPython, Java로 구현한 Jpython, 파이선으로 파이썬을 구현한 PyPy 등 파이썬은 대체 가능한, 특정 플랫폼에 맞춰진 구현체를 가지고 있다.
- CPython +De facto: 많이 쓰여서 표준이 되었다.(사실상 표준)
- Library & Tool
- 다양한 종류의 수많은 standard library 기본 탑재
- 다양한 종류의 수많은 open-source libraries
- General Purpose
- General Purpose: Python (범용적) <-> domain specific: R (도메인용, 통계 전문)
- Dynamic Language
- 정적 프로그래밍 언어인 C, C++, 자바와 달리 string, boolean, int 등을 선언할 필요가 없다. 하지만 선언하지 않으면 않을수록 컴퓨터는 할 일이 늘어난다. 따라서 속도가 느리다.
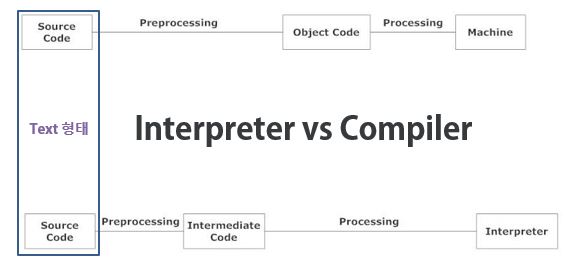
- Interpreted Language
- 인터프리터란 프로그래밍 언어로 작성된 소스 코드를 바로 실행할 수 있는 프로그램 혹은 환경을 의미한다.
- JIT(Just-in-time compilation) 없는 dynamic 인터프리터 언어
- 코드 명령어를 하나씩 읽어 해석하고 바로 실행한다.
- 모바일 지원에 대해 약하다.
Python 버전확인 방법
import sys
sys.version_info
sys.version
# '3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)]'
import platform
platform.python_version()
# '3.7.3'
Python 개발 환경
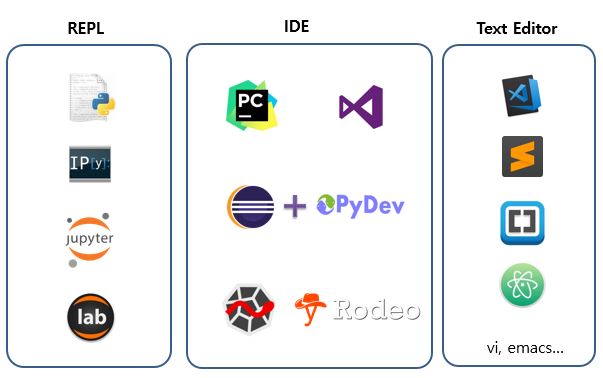
- REPL: Read-Evaluation-Print-loop의 약자로 컴파일 과정없이 즉석으로 코드를 입력하고 실행결과를 바로 보는 대화형 모드 인터프리터를 말합니다.
- IDE: Integrated Development Environment의 약자로 개발통합환경 즉, 코딩을 위한 편집기, 컴파일, 링크, 디버그 등 실행 모듈 개발에 필요한 기능을 한곳에 모아둔 프로그램을 말합니다.
- Text Editor: 문서 편집기, 메모장이나 노트패드, atom 등을 text editor라고 하고 보통 코딩을 위한 text editor는 코딩을 더 편리하게 도와주는 기능이 탑재되어 있습니다.
- atom같은 경우에는 원하는 경우 설치하여 터미널창을 추가할 수도 있고 각 언어별 자동완성기능 등 여러가지 편리한 기능들을 사용할 수 있도록 도와주는 프로그램입니다.
2) Anaconda
Anaconda?
파이선은 오픈소스이기 때문에 같이 버전 업을 하는 경우가 없습니다. 따라서 아나콘다 버전으로 설치하면 버전을 고려를 안해도 됩니다. 즉, 아나콘다는 용량 문제, 관리 문제, 충돌 문제, 버전 호환성 등의 문제를 해결 가능합니다.
Jupyter Notebook?
Jupyter 는 Julia + Python + R을 합쳐 만든 개발도구입니다. Jupyter 프로젝트의 모태는 iPython Notebook이빈다. 최초에는 python만을 위한 쉘과 커널을 제공하였으나, 다양한 언어들에 대한 지원을 위해 Jupyer로 변경하였습니다. Jupyter Notebook은 오픈소스 웹 어플리케이션으로 라이브러리 코드, 등식, 시각화와 설명을 위한 텍스트 등을 포함한 문서를 만들고 공유할 수 있습니다. 주로 데이터 클리닝과 변형, 수치 시뮬레이션, 통계 모델링, 머신 러닝 등에서 사용할 수 있습니다. 주요 특징은 다음과 같습니다.
- 40여종 이상의 다양한 언어를 지원. 다양한 종류의 수많은 standard library와 open-source libraries가 탑재되어 있습니다. 오픈소스 라이브러리는 pip 명령어를 통해 설치할 수 있습니다.
- 노트북 공유(Dropbox, Github, Jupyter Notebook Viewer)
- 실시간 대화형 위젯 (이미지, 비디오, 레이텍스, 자바스크립트)
- 빅데이터 통합(Spark 연동)
◆ 프로그래밍의 구성 요소
- 프로그래밍
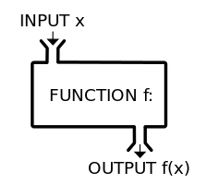
프로그래밍이란 문법(키워드, 식, 문)을 이용하여 값을 입력받고, 계산/변환하고, 출력하는 흐름을 만드는 일입니다.
◆ 파이썬
* 문법(keyword)
- 파이썬은 35개의 문법으로 다른 언어들에 비해 적은 keyword 개수를 가지고 있어서, 배우기가 수월합니다.
기본 문법(keyword) 확인하는 방법
import keyword
keyword.kwlist
'''
['False',
'None', # return 값이 없다.
'True',
'and', # 앞에게 True 이면 뒤에 것 호출 (4 and 3 : 3)
'as',
'assert',
'async',
'await',
'break',
'class',
'continue',
'def',
'del',
'elif',
'else',
'except',
'finally',
'for',
'from',
'global',
'if',
'import',
'in',
'is',
'lambda',
'nonlocal',
'not',
'or', # 앞에게 True 이면 앞에 것 호출 (4 or 3 : 4)
'pass',
'raise',
'return',
'try',
'while',
'with',
'yield']
'''
* 표현식(Expression) = 평가식 = 식
xxx = xxx
식별자 or 변수 = 식(Expression)
- ‘식’이란 값들과 연산자를 함께 사용하여 하나의 값으로 축약(reduction)할 수 있는 것입니다.
ex) 3 + 1 , float(‘inf’) 등
Expression(표현식) vs Statement(구문)
Expression은 값 또는 값들과 연산자를 함께 사용해서 표현해 하나의 값으로 수렴하는 것입니다.
이때 함수, 식별자, 할당 연산자 [], 등을 포함합니다.
그리고 Expression은 평가가 가능하기 때문에 하나의 값으로 수렴합니다.
여기서 평가라는 의미를 정확하게 알고 있어야 합니다. 평가란 컴퓨터가 이해할 수 있는 기계 이진 코드로 값을 변환하면 리터럴의 형태가 달라도 그 평가값은 같게 되는 것을 말합니다.
ex)
a, b = 4, 5
eval('1+2+3')
eval('a+b')
:6
:9
* 문(Statement)
Statement는 예약어와 표현식을 결합한 패턴입니다. 그리고 실행가능한 최소의 독립적인 코드 조각을 일컫습니다. Statement는 총 5가지 경우가 있습니다.
- 할당 (Assignment)
- 반복문 (for, while)
- 조건 (if)
- 예외처리 (EAFP)
- 선언 (Declaration)
Type: 숫자 & 문자
값에 대한 다양한 타입들이 존재합니다. 타입에 따라 서로 다른 기술적인 체계가 필요합니다. 숫자형으로 4가지의 타입이 존재하고, 문자형으로 3가지의 타입이 존재합니다. 이를 알아보도록 하겠습니다.
- 숫자: 4가지(int, float, complex, Boolean)
- int(정수): 양수, 0, 음수(-)
- 콤마는 찍을 수 없다. 하지만 대신에 ‘_‘를 쓸 수 있다. ex) 1_000
- 이진법(0b1); 팔진법(0o7); 십육진법(0xf); 십진법
- float(실수)
- b = 0.1
- c = 1e3 = 1000.0
- complex(복소수)
- d = 1 + 3j
- Boolean
- True == 1
- False == 0
- issubclass(bool, int) # bool이 int로부터 상속받았다.
- int(정수): 양수, 0, 음수(-)
- 문자: 3가지(str, bytes, bytearray)
- str(string)
- ‘안녕’
- bytes
- b’안녕’
- bytearray
- str(string)
**isinstance & issubclass**
isinstance는 어떤 객체가 특정 클래스인치 판별하는 predicate
issubclass는 어떤 클래스가 특정 클래스의 상속을 받았는지 판별하는 predicate
## 숫자 산술연산
3 * 4
# 12
10 / 3
# 3.3333333333333
10 // 3 # 몫
# 3
10 % 3 # 나머지
# 1
10 / -3
# -3.333333333333
10 // -3
# -4
10 % -3
# -2
# 위와 같이 계산하는 이유는 다음과 같다: -3 * (-4) + (-2) = 10
2**4
# 16 = 2^4
## float
a = 1.
type(a)
# float
b = 1e3
type(b)
# float
## 문자
a = '니하오'
type(a)
# str
b = b'abc'
type(b)
# bytes
- 리터럴 방식: 리터럴은 특수한 문자를 통해 데이터 타입을 결정하는 기호를 일컫는 말입니다.
a = 1. # 여기에서 .(점)은 리터럴로 float 타입으로 바꿔줍니다.
for문으로 변수 할당하기
# statement
for i in range(1, 20+1):
exec('r' + str(i) + '=' +str(i))
# r1, r2 ...r20 까지 1,2,...20 할당
결론적으로 모든 Expression은 Statement지만 어떤 Statement는 expression이지 않습니다. retrun 3 이런 구문은 평가를 통해 3의 값이 나오는 것이 아니기 때문입니다.
ex) exec(‘1+2’)는 문제 없지만 eval(‘a=3’)는 오류가 납니다.
할당문
할당(assignments)
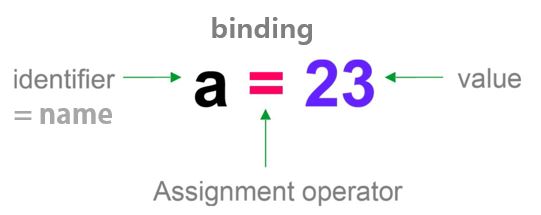
- 할당 (assignments)
- (식별자: name, identifier) a=1 (표현식: 하나의 결과값으로 축약할 수 있는 것)
* 식: 하나의 값으로 축약할 수 있는 것 (reduction) * 표준 (standard, de facto, recommendation)
* 이름 다 대문자: 상수 취급 (파이썬은 상수가 없는 언어)
* 이름 다 소문자: Module(file)
* 두꺼운 초록색: 파이썬 문법(키워드)
* 얇은 초록색: 파이썬 내장 함수
- import builtins \ dir(builtins) - 식별자(name)을 붙이는 규칙 PEP 8 coding style guide
- 이름은 영문자 쓰는 것을 추천
- 이름의 첫글자에 숫자, 특수문자 또는 문법이 들어가면 안된다. 1a = 1 (x), import = 1 (x)
- 단, 예외로 _가 문자 앞에 들어가는 것은 괜찮다. _a = 1 (o)
* 카멜방식(두단어 이상 연결할 때 두번째 문자를 대문자) 클래스 이름 만들 때 ex) moonBeauty
* 파스칼방식 ex) MoonBeauty
* snake방식-함수이름 ex) moon_beauty
* 다 대문자: 상수 취급 - 사실 파이썬은 상수가 없는 언어이다.
* 헝가리안방식: 접두어에 자료형을 붙이는 것 ex) strName, bBusy, szName (별로 사용 안함)
* 이름에 _(*)가 붙어 있으면 import 할 때 실행이 인된다. 이러한 규칙들은 언어레퍼런스에서 찾아볼 수 있다.
* 표현식: ex) 3 if a>0 else 5
* 표현식의 종류: 람다- 함수식, etc - a=1 가 만들어지면
1) 메모리의 공간 할당
2) 메모리 이름 생성 - binding 되는 것
- (식별자: name, identifier) a=1 (표현식: 하나의 결과값으로 축약할 수 있는 것)
Container (원소를 여러가지 가질 수 있는 자료 구조)
자료형을 구별하는 기준
- Mutable: 추가, 삭제가 가능한 경우 (ex. append, extend)
- bytesarray, set, dict, list
- 특징: 메모리 번지가 안바뀐다, 재할당할 필요가 없다, 속도가 좀 느리다.
- Immutable: 추가, 삭제가 불가능한 경우
- tuple, frozenset
- 특징: 재할당으로 메모리 번지 바뀐다, 속도가 좀 더 빠르다.
- homogeneous: range, str, bytes, btearray
- 요소들이 서로 같은 타입
- heterogeneous: list, tuple, set, dict
- 요소들이 서로 다른 타입
- dict: 없는 것을 추가시킬 수 있다.
key = hashable(해쉬가 가능한 것만 올 수 있다.)
- sequence: list, tuple, range, str, bytes, bytearray
- 순서가 중요한 타입
- index, slicing을 쓸 수 있다.
- non-sequence: set, dict
- index, slicing 못 쓴다.
Indexing
- 하나씩 뽑아서 쓸 수 있는 것
a = '안녕하세요'
a[0]
# '안'
a[-1] # 뒤에서부터 시작한다.
# '요'
Slicing
- 두단어 이상 뽑아서 쓸 수 있는 것
- 중간에 ‘:’이 들어갑니다.
a[0:2]
# '안녕'
a[:2] # :이 먼저 들어가면 처음부터라는 뜻
# '안녕'
a[-3:] # :이 마지막에 들어가면 마지막까지라는 뜻
# '하세요'
list vs. tuple
- heterogeneous
- sequence (index, slicing)
차이점 List는 수정, 삭제, 추가가 가능하지만, Tuple은 수정, 삭제, 추가가 불가능합니다.
## list
b = [1,2,'1'] # 1,2는 int, '1'은 str -> 이처럼 다른 타입을 포함할 수 있는 것을 heterogeneous라고 한다.
type(b)
# list - 추가 삭제가 가능하다. (mutable)
## tuple
c = (1,) # 콤마 없이 (1) 이라고 하면 type이 int로 나온다.
c = 1, # 이렇게 해도 tuple로 인식 한다.
c = (1,2,'1',) # 뒤에 콤마를 씀으로 가독성을 높이고, tuple로 인식될 수 있다.
type(c)
# tuple - 자기자신을 바꿀 수 없다. (immutable): 따라서 속도가 좀 더 빠르다.
c.count(1) # c tuple에 있는 값을 세어준다.
# 1
c.index(1) # c tuple에 있는 값의 index를 알려준다.
# 0
set vs. dictionary
- heterogeneous
- not sequence 이므로 index, slicing을 할 수 없습니다.
- 순서를 고려 안하고 가져오므로 속도가 빠릅니다.
차이점 set은 key값만 있는 반면 dictionary는 key, value 쌍을 이루어 mapping hash 타입을 이룹니다.
## set
d = {1,2,'1',1,1,1}
d
# {1,'1',2} -> 집합은 내가 순서를 정할 수 없고, 중복이 없다.
type(d)
# set
## dict
e = {'a':1, 'b':[1,2]} # 'a', 'b'를 keys라고 하고, 1,[1,2]가 values라고 한다.
type(e)
# dict
e.keys()
# dict_keys(['a', 'b'])
e.values()
# dict_values([1, [1, 2]])
e.items()
# dict_items([('a', 1), ('b', [1, 2])])
e['c'] = 3 # dict은 이렇게 새로운 값들을 추가시킬 수 있다.
e
# {'a': 1, 'b': [1, 2], 'c': 3}
2019년 11월 5일
set vs. frozenset
- set
- heterogeneous
- mutable
- none sequence
- 집합 연산 지원해줍니다.
- frozenset
- immutable (자기자신이 바뀔 수 없는 것)
## set
a = {1,2,3}
b = {3,4,5}
a|b # 핮집합
# {1,2,3,4,5}
a&b # 교집합
# {3}
a^b # 차집합
# {1,2,4,5}
## frozenset
a = frozenset({1,2,3})
b = frozenset({3,4,5})
a&b
# frozenset({3})
할당 6가지
-
기본 할당문
a = 1 - 증감 할당 (Augmentation)
- (전치 증감; ++b (b+=1) -> 파이썬에는 없다.)
a += 1
- (전치 증감; ++b (b+=1) -> 파이썬에는 없다.)
-
Chain assignment
a = b = 1 주의 (1) copy 개념이 나온다. (추후 배울 예정) -
Packing
x = 1,2,3,
y = 1, # 뒤에 콤마를 붙이면 tuple 타입이 된다. - Unpacking
- Container 쪼개기
- 내부적으로 정해진 순서의 짝을 맞춰준다.
a, b = 1, 2
a, b = b, a+b
a, b = (1,2) ; [1,2] ; {1,2}
- Global, nonlocal
- global 이용하여 전역번수 접근, 변경하기
+ 함수 밖에서 함수 안에서 접근할 수 없다. 함수 안에서는 함수 밖에거 접근할 수 있는데, 그 경우는 안에 값이 없을 때이다. 하지만 값을 바꿀 수는 없다.
- nonlocal은 함수 중첩시 함수와 함수 사이 변수
- global과 nonlocal은 쓰지 않는 것을 추천한다.
- global 이용하여 전역번수 접근, 변경하기
+ 함수 밖에서 함수 안에서 접근할 수 없다. 함수 안에서는 함수 밖에거 접근할 수 있는데, 그 경우는 안에 값이 없을 때이다. 하지만 값을 바꿀 수는 없다.
## 5. unpacking
x, y = 1,2 (o)
x, y, *z = 1,2,3,4 (o) # 나머지 값이 z에 할당된다. x=1, y=2, z=[3,4]
*x, = 1,2,3 (o) # type이 list가 된다. [1,2,3]
*a, = '안녕'(o) # ['안녕']
*u, = {'a':1, 'b':2, 'c':3} (o) # 단, 키 값만 리스트 형태로 변환 [a,b,c]
*x, y = range(10) (o)
x, = 1,2 (x) # 왼쪽 식별자와 오른쪽 식의 개수를 맞춰야한다.
*x, y, *z = 1,2,3,4,5 (x) # *x 는 나머지를 값을 취한다는 것을 의미한다. 나머지가 2개를 쓰면 충돌
*x = 1,2,3 (x) # 나머지라는 개념이 맞지않으면 충돌
# *(별표)는 나머지를 리스트로 반환, 그리고 *를 두 개 이상을 못쓴다.
# 함수 안에 있는 변수를 local 변수라고 한다.
# 함수를 감싸고 있는 변수를 enclosing 변수, 또는 nonlocal 변수라고 한다.
# 함수 밖에 있는 변수를 global 변수라고 한다.
## 6. global
def t():
bbb = 4
return aaaaa
aaaaa = 3
t()
# 3
def t():
global aaaa # 함수 안에 있는 것과 밖에 있는 것의 싱크를 맞춰서 사용한다는 뜻이다.
aaaa+= 1
return aaaa
aaaa = 3
t()
# 4
## 6. nonlocal
xxx = 3
def t():
xxx = 1
def s():
# global xxx
nonlocal xxx
return xxx
return s()
t()
# 1
xxx = 3
def t():
xxx = 1
def s():
nonlocal xxx
return xxx
return s()
t()
# 1
반복문 5가지
- for
- While
- break
- continue
-
else
- for, while에는 else쓰지 않는 것을 권장합니다.(다른 언어에서는 쓰이지 않는 기법이므로)
for 문
- element base
- 모든 for 는 while로 바꿀 수 있지만, while은 for로 못 바꿉니다.
- 파이썬은 순수한 객체 지향이기 때문에 사람들은 for을 훨씬 더 좋아합니다.
-
하지만 for문을 중첩해서 쓰게되면 속도가 느려지는 단점이 있습니다.
- ‘in’ keyword는 값이 있는지 없는지 확인해 주는 keyword입니다. 이를 membership이라고 합니다.
- for구문을 이용해서 반복문을 만들 수 있습니다.
- for _ in container : 여기서 in 다음에 container(iterable)가 오면 하나씩 뽑아서 반복문이 형성됩니다.
iterator 메모리 효율을 극대화시킬 수 있는 것이 iterator라는 것입니다. 또한 속도도 빠르고 실행시 메모리를 할당합니다. 대신 구동할 때마다 속도차이가 있습니다. iterable은 파이썬에 아주 많습니다.
iterable iterator로 바꿀 수 있는 것으로 순회, 반복 가능한 것(요소 하나씩 뽑아냄)입니다. for 뒤에 사용할 수 있는 container 이고, container은 다 iterable 입니다.
membership
- 특정한 집합에 어떤 멤버가 속해있는지를 판단하는 것으로 비교연산에 기반을 둡니다.
- is, is not : 값의 크기가 아닌 값 자체의 정체성(identity)이 완전히 동일한지를 검사
- in, not in : 멤버십 연산. 어떠한 집합 내에 원소가 포함되는지를 검사 (‘a’ in ‘apple’)
3 in [1,2,3]
# True
'3' not in [1,2,3]
# True
for i in range(10):
print(i)
# 0
# 1
# 2 ...
temp = 0
for j in range(1,11):
temp = temp + j
print(j, temp)
# 1 1
# 2 3
# 3 6
# 4 10
# 5 15 ...
for k in '안녕하세요': # string 도 container 중 하나이다.
print(k)
# 안
# 녕
# 하 ...
while문
- index base
a = 10
while a>0:
print('a')
a = a-1
# a
# a ... (10번 출력)
break, continue
# for, while안에서는 break, continue를 쓸 수 있다.
for i in range(3):
if i == 5 :
continue
print(i)
else:
print('END')
# 0
# 1
# 2
# END
for i in range(10):
if i == 5 :
break
print(i)
else:
print('END')
# 0
# 1
# 2
# 3
# 4
조건문
조건문 형태 3가지
- if, else, and, or
- if, elif, else
- 중첩 if
a = -10
if a>3:
print('T')
elif a> -20 :
print('FF')
else:
print('F')
# FF
if [1,2,3]: # 공집합은 False, 값이 있으면 True
print('T')
else:
print('F')
# T
if float():
print('T')
else:
print('F')
# F
if None:
print('T')
else:
print('F')
# F
조건문과 반복문은 중첩해서 쓸 수 있다.
for i in range(1,10):
if i%2 ==0 :
print(3, '*', i, '=', 3*i)
# 3 * 2 = 6
# 3 * 4 = 12
# 3 * 6 = 18
# 3 * 8 = 24
# for, while에 else를 붙일 수 있다.
for i in range(1,3):
print(i)
else:
print('END')
# 1
# 2
# END
예외 처리
print 찍는 것 보다 파이썬 자체에서는 에러를 발생시킵니다. 이는 파이썬은 EAFP(Easier to ask for forgiveness than permission)라는 것을 보여줍니다. 파이썬의 철학이 ‘허락보다는 용서를 구하기가 쉽다’라는 것입니다. 따라서 에러를 발생시키면서 프로그램을 진행시키는 게 좋습니다. print를 하면서 일일이 찾기보다는 에러 발생시키는 것을 더 좋아합니다.
이렇게 하는 이유는 파이썬은 느린언어이기 때문입니다. 속도를 조금이라도 빠르게하고 코딩 흐름을 우아하게 하기 위해서 에러를 발생시키는 것을 추천합니다.
이와 반대되는것은 C와 같은 다른 언어에서 자주 사용되는 LBYL 스타일이라고합니다.
하지만 DataSicence 분에야서는 많이 사용하지 않습니다. 웹이나 자동화 등 사용자로부터 입력을 받거나 외부 조건에 의해 오류가 많이 날 수 밖에 없는 환경에서는 굉장히 중요합니다. 따라서 오류가 나더라도 중단하지 않고 실행 시켜야 하는 경우 대비해서 예외처리문을 삽입하는 것입니다.
i = 10
assert 1 > = 11
# False가 오면 Error 를 발생시킨다.
if i >1:
raise Exception # 다음과 같은 조건일 때 에러를 강제로 발생해줄 수 있다.
# runtime error을 지정해 줄수도 있다.
논리가 안맞아서 에러가 나는 RUNTIME 에러를 잡아낼 수 있습니다. 문법은 맞춰야합니다. 에러를 잡아내기 위한 구조는 크게 4가지가 있습니다.
- try:
- except: 에러가 나면 except 구문이 실행
- else: 에러가 나지 않으면 else 구문이 실행
- finally: 에러 상관없이 실행
- Runtime
어떤 프로그램이 실행되는 동안 발생하는 에러를 말합니다.
try:
1/0
except ZeroDivisionError:
print('Zero')
except: # 나머지 모든 에러에 대해 처리해 주겠다는 것. 따라서 맨 끝에 적어야한다.
print('e') # 에러가나면 except 구문이 실행된다.
else:
print('else') # 에러가 나지 않으면 실행
finally:
print('finally')
# Zero
# finally
try:
1/0
except ZeroDivisionError: # error 조건을 줄 수 있다.
print('Zero')
# Zero
try:
1/0
except Exception as e:
print(Exception.__repr__) # REPL 개념을 또 알아야 한다.
# <slot wrapper '__repr__' of 'BaseException' objects>
‘as’ 3가지 용법
except as : as는 앞에 나오는 예외처리 클래스의 인스턴스를 받는다. with as : assignment 이다. (with open as e:) import as : 이름하고 똑같이 쓰는 것이다.
선언문
선언문 : 재사용 가능한 독립적인 단위를 정의하는 것
- 함수 선언: 스네이크 방식 (소문자, 언더바)
- 클래스 선언
argument(인자)와 parameter(매개변수)차이
- Parameter : 선언문에서 괄호 안에 쓰는 변수를 매개변수(Parameter)라고 합니다.
-
Argument : 함수를 호출할 때 함수 (또는 메서드) 로 전달되는 값이 인자(Argument)입니다.
- 인자와 매개변수에 관한 보다 자세한 내용은 추후에 나옵니다.
파이썬은 오버로딩을 지원하지 않습니다. 보통 다른 언어에서 매개변수가 다르면 다른 함수로 취급하는 것을 오버로딩이라고 합니다.
- ex) a(x), a(x,y), a(x,y,z) 파이선은 오버로딩을 지원하지 않기 때문에 따라서 이름만 같으면 매개변수를 보지 않습니다. 따라서 인자를 나눠서 만들 수 없기 때문에, 가능한 모든 인자를 집어 넣습니다.
- ex) def x(*a, **b) # *가변 포지셔널 , **가변 키워드
2019년 11월 6일
함수
- 함수를 만드는 두가지 방식
- Lambda(익명함수)
- 선언
# 람다
a = lambda x:x**6 # 함수식/ 함수를 만들고, 인스턴스를 통해 괄호를 붙일 수 있다.
a(4) # 매개변수와 인자의 수를 맞춰야한다.
# 4096
# 선언
def u(x):
return x**6
u(4)
# 4096
- 함수 사용하는 목적 (클래스도 같은 목적을 가진다.)
- 캡슐화(Encapsulation)
- 함수 밖에서 함수 안에서 접근할 수 없다. 함수 안에서는 함수 밖에거 접근할 수 있는데, 그 경우는 안에 값이 없을 때이다. 하지만 값을 바꿀 수는 없다.
- 재사용
- 선언문(declaration): 함수, 클래스
- 컴파일러에게 사용될 요소(이름)을 알려주는 것
-
정의문(definition): 코드나 데이터 가은 요소(이름)를 구체적으로 명시한 것
- 함수의 이름 정의 (PEP8)[https://www.python.org/dev/peps/pep-0008/]
- PEP8에 의해 함수의 이름은 소문자, snake 방식으로 쓰는 것을 권장한다.
def cho(parameter): # 괄호 안에 넣는 것을 파라미터라고 한다.
return parameter
cho(3) # () 안에 넣는 것을 인자라고 한다.
# 3
def cho(a):
pass # 이름만 확보해 놓기 위해 해놓은 것.
# pass는 아무 기능이 없다.
def x(a):
'''설명''' # shift+tap하면 Docstring에 설명이 적혀있다.
return a + 1 # 차례대로 들어가는 것을 포지셔널 방식이라고 한다.
x(3)
# 4
def star():
print('111')
star
# <function __main__.star()> --> __main__: 현재 작업하고 있는 공간에 있는 경우
len # builtins(내장 함수) 의 경우 __main__이 나타나지 않는다.
# <function len(obj, /)>
Parameter(매개변수)
- 총 5-7가지의 매개변수가 있습니다. 여기서는 6가지로 정리하도록 하겠습니다.
- 함수 (또는 메서드) 정의에서 함수가 받을 수 있는 인자 (또는 어떤 경우 인자들)를 지정하는 이름 붙은 엔티티입니다.
- 매개변수와 인자의 개수는 같아야 합니다.
- 따라서 매개변수는 선언문 내 default 값입니다.
- Positional + keyword
- 포지션널 방식
- x(2) 와 같이 값으로 제공될 수 있는 인자
- 순서를 확인하므로, 처음부터 순서에 맞게 써야합니다.
- 키워드 방식
- 키워드란 이름을 두면서 사용하는 방식 x(a=2)
- 순서 상관없이 이름 찾아갑니다.
- 한번 키워드 방식을 쓰게 되면 그 다음부터는 키워드를 써야합니다.
- 위치 인자 나 키워드 인자 로 전달될 수 있는 인자를 지정합니다. 이것이 기본 형태의 매개변수입니다. 예를 들어 다음에서 foo 와 bar:
- def func(foo, bar=None): … # foo: 포지셔널/ bar: 키워드
- Only Positional
- def func(foo, bar=None): … # foo: 포지셔널/ bar: 키워드
- (위치로만 제공될 수 있는 인자를 지정합니다. 파이썬은 위치-전용 매개변수를 정의하는 문법을 갖고 있지 않습니다. 하지만, 어떤 매장 함수들은 위치-전용 매개변수를 갖습니다. (예를 들어, sum(…, /)).
- Only Keyword
- 키워드로만 제공될 수 있는 인자를 지정합니다. 키워드-전용 매개변수는 함수 정의의 매개변수 목록에서 앞에 하나의 가변-위치 매개변수나 * 를 그대로 포함해서 정의할 수 있습니다. 예를 들어, 다음에서 kw_only1 와 kw_only2:
- def func(arg, *, kw_only1, kw_only2): …
- Variable Positional (가변 포지셔널)
- def func(arg, *, kw_only1, kw_only2): …
- (*a) 이름 앞에 *가 붙으면 가변 포지셔널입니다.
- 개수와 상관없이 계속 쓸 수 있습니다.
- 리턴이 tuple로 나옵니다.
- (다른 매개변수들에 의해서 이미 받아들여진 위치 인자들에 더해) 제공될 수 있는 위치 인자들의 임의의 시퀀스를 지정합니다. 이런 매개변수는 매개변수 이름에 * 를 앞에 붙여서 정의될 수 있습니다, 예를 들어 다음에서 args:
- def func(*args): …
- Variable keyword (가변 키워드)
- def func(*args): …
- (**a) 이름 앞에 **가 붙으면 가변 키워드 방식입니다.
- 개수와 상관없이 계속 쓸 수 있습니다.
- 리턴이 dict으로 나옵니다.
- (다른 매개변수들에 의해서 이미 받아들여진 키워드 인자들에 더해) 제공될 수 있는 임의의 개수 키워드 인자들을 지정합니다. 이런 매개변수는 매개변수 이름에 ** 를 앞에 붙여서 정의될 수 있습니다, 예를 들어 위의 예 에서 kwargs.
- def func(**kwargs): …
- Variable Positional + Variable keyword
- def func(*args, **kwargs): …
- def func(**kwargs): …
- 따라서 매개변수는 선언문 내 default 값입니다.
- 매개변수는 선택적 인자들을 위한 기본값뿐만 아니라 선택적이거나 필수 인자들을 지정할 수 있.
# Positional + Keyword #
def name(a,b):
''' 함수 설명 ''' # Docs String => Shift + Tab 하면 설명이 그대로 나온다
return a, b # 참고로 함수 설명에 ( / )가 있을 경우 Positional 방식이라는 뜻
name(1,2)
:(1,2)
name(3, b = 4)
:(3,4)
name(a=1,b=2)
:(1,2)
def x(a,b=3,c=4):
return a,b,c
# 선언할 때 쓰는 안에 들어가는 것을 매개변수(parameter)이라고 한다.
x(4,b=3,c=2) # argument라고 한다.
# 한번 키워드 쓰면 b=2 그 다음부터는 키워드 방식으로 써야한다.
# (4, 3, 2)
# 별표 다음에는 무조건 키워드 방식을 써야한다.
def y(*, a):
return a
y(a=3)
# 3
# *(별표) 앞에가 포지셔널 방식, 뒤에는 키워드 방식
def cho(a,b = 4 , *, c= 5):
return a +b + c
cho(3,4, c=6)
# 13
# 별표에 이름을 붙이면, 가변 포지셔널 방식이다. 개수 안맞춰도 계속 쓸 수 있다.
def y(*a):
return a
y(1,2)
# 1,2
def y(*b, **a): # 가변 포지셔널, 가변 키워드
return b,a
y(3,4,1,a=3,b=2)
# ((3, 4, 1), {'a': 3, 'b': 2})
# 포지셔널 온리
sum([3,2,4], 22) # /: 포지셔널 온리
# 31
# unpacking
def cho(*a,**b): # 가변 포지셔널, 가변 키워드 순서로 넣는다.
return a,b
x=[1,2,3,4]
cho(*x) # 쪼개져서 들어간다.
# ((1, 2, 3, 4), {})
y={'a':1, 'b':2,'c':3}
[*y] # keys 만 나온다.
cho(*x,**y) # dictionary는 **넣으면 가변키워드에 들어가진다.
# ((1, 2, 3, 4), {'a': 1, 'b': 2, 'c': 3})
Argument(인자)
- 함수를 호출할 때 함수 (또는 메서드)로 전달되는 값
- 키워드 인자 (keyword argument)
- 함수 호출 때 식별자가 앞에 붙은 인자 (예를 들어, name=) 또는 ** 를 앞에 붙인 딕셔너리로 전달되는 인자. 예를 들어, 다음과 같은 complex() 호출에서 3 과 5 는 모두 키워드 인자:
- complex(real =3 , imag =5)
- complex(\n**{‘real’:3, ‘imag’: 5})
- 위치 인자 (positional argument)
- 키워드 인자가 아닌 인자. 위치 인자들은 인자 목록의 처음에 나오거나 이터러블 의 앞에 * 를 붙여 전달할 수 있음. 예를 들어, 다음과 같은 호출에서 3 과 5 는 모두 위치 인자.
- complex(3,5)
- complex(\n*(3, 5))
별표(*)의 총 7가지 방법
- Unpacking 방법에서 나머지
- Only keyword
- Variable Positional
- Variable Keyword
- Unpacking (벗겨내기, list 쪼개기)
- Unpacking (dictionary)
- import *에서 모두 불러오기 (안 쓰는 것을 추천)
annotation
annotation (어노테이션)관습에 따라 형 힌트로 사용되는 변수, 클래스 어트리뷰트 또는 함수 매개변수나 반환 값과 연결된 레이블로 사용자한테 제공할 문서로 만들기가 좋습니다.
- 지역 변수의 어노테이션은 실행 시간에 액세스할 수 없지만, 전역 변수, 클래스 속성 및 함수의 어노테이션은 각각 모듈, 클래스, 함수의 annotations 특수 어트리뷰트에 저장됩니다.
def xx(x: int) -> int:
return x # 리턴이 int형으로 나온다.
xx('hi')
# 'hi'
xx.__annotations__
# {'x': int, 'return': int} # 타입을 표시해줍니다.
함수의 중첩으로 가능한 것들
- Closure
- Decorator
Closure
함수를 중첩시키고 함수를 리턴하는 함수입니다. 클로저는 보통 함수를 쉽게 변형할 수 있는 기법입니다.
def a(x):
def b(y):
return x + y
return b
# 3더해주는 함수
a(3)(10)
# 13
# 4더해주는 함수
a(4)(10)
# 14
Decorator
함수나 클래스를 추가, 수정하여 재사용 가능하게 해주는 것입니다. 데코레이터를 사용하려면 함수 중첩이 있어야하고, 함수를 파라미터로 받고, 중첩된 inner 함수를 return 해야합니다.
예제로 Decorator 이해하기
- 중첩 X, 함수 리턴 X 일 경우: 데코레이터가 아니다.
- 함수 return X, 문자열 return일 경우: 데코리에터가 아니다.
- 함수 return X, 함수 호출 return일 경우: 데코레이터가 아니다.
- Annotation(java에서는 @를 annotation이라고 부른다)이 없는 경우입니다.
- 함수 파라미터 O, 함수 중첩, 함수 이름 return O: 데코레이터이다.
중첩X, 함수 리턴X 일 경우
- 데코레이터가 아닙니다.
def login_check(fn):
id = input('id: ')
if (id == 'ch'):
print('ch님 안녕하세요.')
fn()
else:
print('존재하지 않는 회원입니다.')
@login_check
def home():
print('ch님의 홈페이지 입니다.')
'''
# ch 입력시
id: ch
ch님 안녕하세요.
ch님의 홈페이지 입니다.
# cho 입력시
id: cho
존재하지 않는 회원입니다.
'''
callable(home)
# False
callable(login_check)
# True
함수 return X, 문자열 return일 경우
- 당연한 결과지만 login_check함수 안에서 inner 함수를 return 하지 않으면 inner함수를 사용할 방법이 없습니다. 그리고 함수위에 ‘@login_check’을 사용하면 @밑으로 함수선언을 하게되면 @밑 함수는 ‘@login_check’의 인자로 들어가게 됩니다. 결국 ‘@함수이름’의 return값이 함수이름이 아니게되면 @밑에 선언된 함수는 not callable이게 됩니다. 따라서 데코레이터가 아닙니다.
def login_check(fn):
def inner():
id = input('id: ')
if(id=='ch'):
print("ch님 안녕하세요")
fn()
else:
print("존재하지 않는 회원입니다")
print('출력')
return 'a'
# 출력
home
# 'a'
callable(home)
# False
callbable(login_check)
# True
함수 return X, 함수 호출 return 일 경우
- 함수 return X, 문자열 return일 때와 결과가 같습니다. 이로써 ‘@login_check’을 사용하면 밑에 선언된 함수는 login_check함수의 인자로 들어가 login_check함수의 return 값을 반환한다는 사실이 확실해졌습니다. login_check함수의 return 값은 inner함수 호출이고 inner함수의 호출값의 return은 None 이기 때문에 home함수의 return 값은 None 입니다. 따라서 데코레이터는 아닙니다.
def login_check(fn):
def inner():
id = input('id: ')
if(id=='ch'):
print("ch님 안녕하세요")
fn()
else:
print("존재하지 않는 회원입니다")
return inner()
@login_check
def home():
print("ch님의 home page 입니다")
# ch 입력시
id: ch
ch님 안녕하세요
ch님의 home page 입니다
# cho 입력시
id: cho
존재하지 않는 회원입니다
callable(home)
# False
callbable(login_check)
# True
함수 파라미터 O, 함수 중첩, 함수 이름 return O 인 경우
- callable(home)했을 때 True가 나오므로 데코레이터가 맞습니다! (home함수에 login_check함수 기능 추가)
def login_check(fn):
def inner():
id = input('id: ')
if(id=='ch'):
print("ch님 안녕하세요")
fn()
else:
print("존재하지 않는 회원입니다")
return inner
@login_check
def home():
print("ch님의 home page 입니다")
home()
# ch를 입력 시
id: ch
ch님 안녕하세요
ch님의 home page 입니다
callable(home)
# True
callbable(login_check)
# True
함수형 프로그래밍
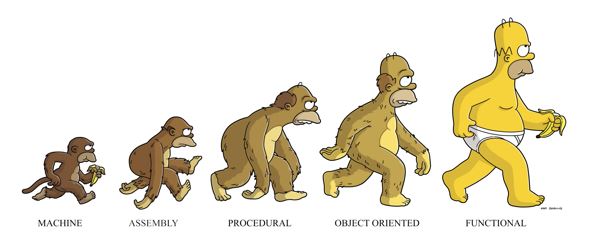
함수형 프로그램잉은 계산을 수학 함수로 취급하고 state 및 mutable 데이터를 피하는 프로그래밍 패러다임입니다. 다시 말해, 함수형 패러다임은 mutable이 없습니다. 또한, 부작용 없이 변수의 값을 변경하지 않고, 코드를 실행시킵니다. 함수형 프로그래밍이 주목받는 이유는 분산처리를 할 수 있기 때문입니다. 멀티 프로세싱 기법에 최적화된 패러다임으로 빅데이터 처리시 효율적입니다. 수학처럼 추상화시켰기 때문에 코드가 짧고, 디버그하기가 쉽습니다.
함수형 프로그램밍의 특징
- 코드가 간결해진다.
- 내부 구조를 몰라도 input, output만 알면 사용 가능
- 수학적으로 증명이 가능하다.
- for, while문을 자제하고 iter를 사용한다.
- for를 쓰면 안좋은 점 2가지
(1) 코드가 길어질 때, 흐름찾기가 어렵다.
(2) 명령이 많아지므로 속도가 느려진다.
- for를 쓰면 안좋은 점 2가지
- 수학적 증명이 필요하기 때문에 구현이 어렵다.
- 단, python에서는 multi paradiam이기 때문에 적절히 혼용 가능
- 디버깅, 테스트가 용이하다.
- 모듈성, 결합성이 있다.
- mutable은 처리하지 않는다.
함수 for를 사용하지 않는 4가지 방법
1) Iterater, generator 2) comprehension 3) map, filter, reduce 4) recursion (재귀)
First class function
- 프로그래밍(타입,값)에서 1등으로 중요한 것은 ‘값’이다.
- function을 객체(값)처럼 사용할 수 있다.
- 함수를 값처럼 사용할 수 있다.
Higher order function
-
정의 2가지
(1) 함수(function)를 인자(argument)로 받을 수 있다.
(2) 함수를 리턴할 수 있다. -
예시로 java는 higher order function이지만 first class function은 아닙니다.
함수, 클래스, 클래스의 call 은 ()(괄호)를 붙일 수 있다. ()를 붙일수있는 여부를 확인하는 내장함수인 callable()를 이용하여 확인해보며뇐다.
def x(f):
f('a') # 파이선에서는 ()를 붙있 수 있는 애들이 3가지 있다.
# x가 함수이다. x에 결과값을 넣으면 리턴값이 된다.
callable(x)
# True
# 함수를 인자로 받을 수 있다.
x(print)
함수를 인자로 받는 경우
- map
- filter
- reduce
- for문을 사용하지 않으므로 속도가 빠르다.
함수 만들 때 lambda를 이용하는 이유는 코드를 실행시킬 때만 함수가 생성되기 때문입니다.
## map: 빅데이터에서 많이 쓴다.
# map(self, /, *args, **kwargs)
# list로 감싸주면 식이 보인다.
list(map(lambda x:x+1, [2,3,4,5])) # 뒤에 iterable을 넣어주면 된다.
# [3, 4, 5, 6]
# 람다는 함수인데, 이름이 없고, 함수식이다. 식이기에 인자에도 들어갈 수 있고, 값에도 할당할 수 있다.
## 속도 비교 (map > comprehension > for)
%%timeit
map(lambda x:x+3, [1,2,3,4,5,6,7,8,9,10])
# 457 ns ± 70.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
%%timeit
[i+3 for i in [1,2,3,4,5,6,7,8,9,10]]
# 850 ns ± 41.5 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
%%timeit
temp = []
for i in [1,2,3,4,5,6,7,8,9,10]:
temp.append(i+3)
# 1.26 µs ± 68.1 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each)
## filter
# 맞는애들만 찾아서 돌려주는 것
list(filter(lambda x:x>4, [2,3,4,5]))
# [5]
## reduce
# python3 에서는 functools 라이브러리 안에 들어가 있다.
from functools import reduce
# import 했으므로 함수이다.
# 값을 줄여주는 기능을 reduction이라고 한다.
# 값을 축약하는 기능이다. (functional paradigm)
# 아주 많이 쓰는 테크닉이다.
reduce(lambda x,y:x+y, [1,2,3,4,5])
# 15
Comprehension
For 문을 쓰지 않고 Iterable한 객체를 생성하기 위한 방법입니다. List, Set, Dictionary 형식으로 만들 수 있습니다. 하지만 tuple은 만들지 못합니다. tuple로 변환시키면 Generator가 됩니다.
## list
# for 앞에는 식이 오면된다
a = [(x,y) for x in range(10) for y in range(20)]
# [(0,0),(0,1),(0,2),......(9,19)]
## set
b = {x+1 for x in range(10) if > 5}
# {7, 8, 9, 10}
## dictionary
c = {x:1 for x in range(10) if x>5}
# {6: 1, 7: 1, 8: 1, 9: 1}
## generator 표현식 (tuple)
d = (x for x in range(10))
d
# <generator object <genexpr> at 0x000001EBD5645DE0>
Recursive function (재귀 함수)
파이썬은 Recursion 속도를 지원해주지 않습니다. 따라서 사용하지는 않지만, 개념만 확인하도록 합니다.
## fibonnaci
def fib(num):
if num < 3:
return 1
return fibB(num-1) + fibB(num-2)
fib(10) # 10번째 항 (1 1 2 3 5 8 13 21 34 55)
# 55
Iterator vs. Generator
Iterator는 반복가능한 객체 그리고 데이터 스트림을 표현하는 객체라고 합니다. 예를 들어 list는 반복가능한 자료형 즉 iterable이지만 iterator는 아닙니다. For 문 뒤에 쓸 수 있는 이유는 in 다음에 iterable이 오면 iter 없이 iterator로 변환해주기 때문입니다.
Iterator와 Generator는 비슷하지만 만드는 방식에 차이점이 있습니다. 우선 생성 방식에서 차이가 있고 Generator는 tuple, yield로 만들고 Iterator는 liter() 함수로 만듭니다.
Iterator
iterator 만드는 방법은 간단합니다. iter()로 감싸주면됩니다.
a = iter([1,2,3,4])
next(a)
# 1
Generator
Iterator를 생성해주는 함수로 immutable입니다. 데이터를 하나하나씩 뽑아서 쓸때 사용합니다. 따라서 메모리 관점에서 하나하나씩 뽑아서 쓰기때문에 효율적입니다. 또한 다른 함수와 다르게 next()를 사용할 수 있습니다. 처음부터 모든 데이터를 메모리상에 올리는 것이 아니라 iter할 때마다 메모리 상에 올라갑니다. 이러한 기법을 lazy Evaluation(실행시점에서 메모리 올라가는)기법이라고 합니다.
-
iterator 형제가 generator입니다: 전체 데이터 중에 한개씩 뽑아서 쓰는 것
-
제너레이터 만드는 2가지 1) yield 2) comprehension인데 tuple 형태로 만들면 된다.
- tuple은 immutable이다.
# tuple로 만들기
a = (x for x in range(10))
a
# <generator object <genexpr> at 0x000001EBD55D0DE0>
# yield로 만들기
def x():
yield 1
yield 2
y = x()
next(y)
# 1
주의
Itertools
iterator, generator를 모아둔 것입니다. 따라서 next를 쓸 수 있고, lazy evaluation 기법을 활용하여 메모리상 효율적입니다. 예시로 간단하게 몇개만 보도록 하겠습니다.
- accumulate, count, combinations, chain
from itertools import accumulate, count, combinations, chain
## accumulate
list(accumulate([1,2,3,4]))
# [1, 3, 6, 10]
## count
a = count(3,4)
next(a)
# 3
next(a)
# 7
## combinations
s = combinations([1,2,3,4],2) # [] 중에 2개 뽑는 것
next(s)
# (1,2)
list(s)
# [(1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]
## chain
list(chain([1,2,3],[3,4,5],[2,3,4]))
# [1, 2, 3, 3, 4, 5, 2, 3, 4]
- groupby, repeat, zip_longest, starmap, tee
from itertools import groupby, repeat, zip_longest, starmap, tee
## groupby
x = [('a',1), ('a',2), ('b',2),('c',2), ('a',4), ('c',3)]
t = sorted(x)
s = groupby(t, lambda x:x[0])
list(s)
'''
[('a', <itertools._grouper at 0x27e89b2c0f0>),
('b', <itertools._grouper at 0x27e89b2c128>),
('c', <itertools._grouper at 0x27e89b2c160>)]
'''
s = groupby(sorted(x),lambda x:x[0])
for i in s:
for j in i:
print(i,j)
'''
('a', <itertools._grouper object at 0x0000027E89906E80>) a
('a', <itertools._grouper object at 0x0000027E89906E80>) <itertools._grouper object at 0x0000027E89906E80>
('b', <itertools._grouper object at 0x0000027E89906C18>) b
('b', <itertools._grouper object at 0x0000027E89906C18>) <itertools._grouper object at 0x0000027E89906C18>
('c', <itertools._grouper object at 0x0000027E89912F98>) c
('c', <itertools._grouper object at 0x0000027E89912F98>) <itertools._grouper object at 0x0000027E89912F98>
'''
## repeat
a = repeat([1,2,3],3) # 3번 반복시켜준다.
list(a)
# [[1, 2, 3], [1, 2, 3], [1, 2, 3]]
## zip
t = zip([1,2,3],[4,6],[2,3,4],[6,5,1]) # 순서대로 묶어 준다.
list(t)
# [(1, 4, 2, 6), (2, 6, 3, 5)]
t = zip_longest([1,2,3],[4,6],[2,3,4],[6,5,1])
list(t)
# [(1, 4, 2, 6), (2, 6, 3, 5), (3, None, 4, 1)]
## starmap
k = starmap(lambda x:x>2, [[2],[4],[1]])
next(k)
# False
next(k)
# True
## tee
k = tee([2,3,5,6],3)
list(k[1])
# [2, 3, 5, 6]
함수 Return의 3가지 형태
- 자기는 변하지만 return이 None
- ex) append, extend
- 자기 자신이 변하지 않고 return 값이 있다
- ex) count, index
- 자기 자신도 변하고 return 값도 있다
- ex) pop
# 1
def xx(y, x=[]):
return x.append(y)
# 사실 엉터리 코딩 x.append(y)는 None을 리턴하고,
# 함수 밖에서 x 리스트에 접근도 할 수 없기 때문에 but 인자에 기본값 x list 말고
# 외부에 선언된 list 넣으면 list 확인 가능
# default값을 mutable로 사용하면 heap영역에 들어간다
# 1-1
def xx(list):
return list.append(3)
x = [1,2]
xx(x)
x
: [1,2,3]
# 2
def xx(y, x=[]):
x.append(y)
return x
# xx함수를 호출 할때마다 x 리스트가 계속 변한다
def xx(y):
x = []
x.append(y)
return x
# xx함수를 호출하면 원소가 하나인 리스트 반환
2019년 11월 7일
파이썬 변수의 유효 범위(Scope)
- 유효 범위 규칙(Scope Rule)은 변수에 접근 가능한 범위, 변수가 유효한 문맥범위를 정하는 규칙
LEGB
- Local : 함수 내 정의된 지역변수
- Enclosing Function Local : 함수를 내포하는 또다른 함수 영역
- 함수 안의 함수가 있는 경우 함수와 함수 사이
- Global : 함수 영역에
- Built-in : 내장 영역
- 함수 안의 함수가 있는 경우 함수안의 함수에서 함수 밖의 변수를 사용
우선순위 => L > E > G > B
# LEGB 순서로 찾는다.
a = 1 # global
def y():
a = 2 # enclosing
def x():
a = 3 # local
return a
return x()
객체 지향
- 객체 지향 쓰는 이유
객체 지향 기법이 현재 나와있는 모든 프로그램 기법중에서 유지보수 하는게 제일 편하기 때문입니다.
객체 지향 특징
- 캡슐화(Capsulation)
- 객체의 속성과 행위를 하나로 묶음으로써 실제 구현 내용 일부를 외부에 감추어 은닉하는 것을 의미합니다.
- 재활용 가능
- 파이썬에서는 기본적으로 외부에서 클래스 접근 가능
- descriptor로 클래스 접근을 막을 수도 있다
- 추상화(Abstraction)
- 객체가 가지는 속성(attribute) 및 행위(methods) 중 필요한 것을 뽑아내어 프로그래밍 코드로 작성하는 것을 의미합니다.
- 상속(Inheritance)
- 상위(부모) 객체로부터 하위(자식) 객체가 특징 및 행위를 물려받는 것을 의미합니다. 즉, 추상화한 클래스를 물려받아 구체적으로 원하는 대로 바꾸어 사용 가능합니다.
- 다형성(Polymorphism)
- 같은 이름의 객체가 다양한 결과를 낼 수 있습니다.
- duck typing
- 단순히 메서드나 어트리뷰트가 호출되거나 사용됩니다 (“오리처럼 보이고 오리처럼 꽥꽥댄다면, 그것은 오리다.”)
2019년 11월 8일
클래스
클래스는 ‘변수(Attribute)’와 ‘메소드(Method)’로 이루어져 있습니다. 클래스안에 들어가는 함수를 메소드라고 합니다. 클래스는 쓰기 위해서는 인스턴스화 해주어야합니다. 함수는 행동만 할 수 있지만, 인스턴스는 행동과 값을 가질 수 있습니다. 객체의 클래스는 초기화를 통해 제어됩니다. 이를 통해 복잡한 문제를 다루기 쉽도록 만듭니다.
- 클래스 이름은 카멜방식으로 사용합니다. ex) camelCase
객체(Object)는 소프트웨어 세계에 구현할 대상이고, 이를 구현하기 위한 설계도가 클래스(Class)이며, 이 설계도에 따라 소프트웨어 세계에 구현된 실체가 인스턴스(Instance)입니다.
인스턴스를 하는 이유는 클래스의 정의된 기능과 값을 사용할 수 있기 때문입니다.
type에 인스턴스를 넣었을 때 구체적인 이름이 나오는 인스턴스의 클래스 이름을 알려줍니다. 클래스 이름을 type안에 넣으면 type이 나옵니다. 인스턴스하는 방식은 클래스 이름에 괄호를 붙이는 것입니다. 괄호 안에 넣는 인자는 __init__에 맞춰서 집어 넣습니다.
class C:
x = 1 # 클래스 변수(Class attributes) : 각각 인스턴스들이 공유할 때 클래스 변수를 쓴다.
def a(self): # 인스턴스 메소드
print('A')
def b(self,b):
self.b = b # 인스턴스 변수 : 인스턴드들이 가지는 고유의 값이다. 따라서 공유하지 않는다.
print(self.b)
def c(self):
print('C')
c = C() # 클래스를 통해서 객체를 만들어야 한다. 여기서 c는 인스턴스이다.
c.b(3)
# 3
type(c) # 현재 작업하고 있는 파일에 우리가 정의한 클래스를 __main__이라고 뜬다.
# __main__.C
class T:
x = 1
def __init__(self):
self.x = 2
@property # 인스턴스.y 할 때 ()(괄호)를 붙이지 않아도 된다.
def y(self):
return self.x
@classmethod # 클래스 메소드
def z(cls):
return cls.x
@staticmethod # 클래스 변수, 인스턴스 변수도 안 쓸때 쓴다. 아무 상관 없는 거 쓸 때
def k():
return 1
t = T() # 인스턴스화: t는 인스턴스이자 클래스 T의 객체
T.z() # 클래스 메소드: 클래스 변수를 가져온다.
# 1
t.z() # self는 인자로 안넣어도 된다.
# 1
t.y # 인스턴스 변수를 가져온다. 만약에 인스턴스에 없으면 클래스에서 가져온다.
# 2
t.k()
# 1
T.k()
# 1
오버로딩/오버라이딩
상속: 괄호 안에 집어 넣으면 관계를 맺는 것 이다.
클래스는 괄호 안에 () 안무것도 없으면 Object에서 불러온다.
상속은 크게 2가지
- 단일/다중 : 파이썬은 다중상속 언어이다.
오버로딩/오버라이딩 ( 객체 지향 용어 )
- 오버라이딩: 부모의 있는것 뒤엎어 쓰는것이 오버라이딩이다.
- 오버로딩: 2가지
1) 메소드 오버로딩: a(X), a(X,Y) -> java에서는 이런 것들을 다른 메소드로 따진다.
하지만 파이썬은 메소드 오버로딩을 안 지원해준다. 따라서 이름이 같으면 같은 메소드이다.
2) 오퍼레이터 오버로딩: 연산자 오버로딩 (연산자의 기능을 바꾸는 것이다.)
class A:
x = 1
def __init__(self):
print('A')
def __init__(self, b): # 오버로딩은 지원하지 않기 때문에, 뒤에 것이 앞에 것을 덮어버린다.
print('A')
x = A(b)
# A
class A:
x = 1
def __init__(self, b = None): # 오버로딩을 지원안하므로 default 테크닉을 이용한다.
print('A')
a = A()
# A
super
super는 클래스의 상속받은 부모를 불러와줍니다. 다만, 중복 실행되는 것은 삭제해 줍니다.
class A:
def __init__(self):
print('A')
class B(A):
def __init__(self):
A.__init__(self)
print('B')
class C(A):
def __init__(self):
A.__init__(self)
print('C')
class D(B,C): # B,C 오버라이딩 했다.
def __init__(self):
B.__init__(self)
C.__init__(self)
print('D')
d = D()
'''
A
B
A
C
D
'''
# 어떤 순서로 오버라이딩 되었는가?
# __mro__는 다중 상속 체계를 보여준다.
D.__mro__
# (__main__.D, __main__.B, __main__.C, __main__.A, object)
## super
class A:
def __init__(self):
print('A')
class B(A):
def __init__(self):
super().__init__()
print('B')
class C(A):
def __init__(self):
super().__init__()
print('C')
class D(B,C): # stack으로 실행되므로 먼저 들어온 애가 나중에 나간다. (재귀함수)
def __init__(self):
super().__init__()
print('D')
d = D()
'''
A
C # B가 먼저 들어가기 때문에 C가 먼저 나온다.
B
D
'''
D.__mro__
# (__main__.D, __main__.B, __main__.C, __main__.A, object)
Magic(special) Methods
- ‘__‘는 특수 기능을 가집니다. 어떤 타입의 특징을 기능합니다.
예시
- len : len()
- getitem : [] 인덱싱 가능하게 하는 것입니다.
- init : initialize
- next : 이걸 쓸 수 있으면 iterator 또는 generator입니다.
-
call : 인스턴스에 ()(괄호)를 붙일 수 있습니다.
- duck typing: 오리이다. 특정 기능이 있으면 그 기능처럼 쓸 수 있다.
## __init__
class Init:
def __init__(self,a,b): # PEP8에서 self를 쓰는 것을 추천한다.
# __init__는 생성자로 인스턴스화 할 때 맞춰야하는 양식이다. 매개변수가 2개이므로 인자를 넣을 때 2개를 넣어야한다.
self.a = a
self.b = b
print(a,b)
def a(self,b):
self.b = 4
x = Init(3,5) # __init__ 매개변수 수에 맞춰서 인자를 넣는다.
# 3 5
## __repr__ / __add__
class Summing:
def __init__(self,x): # PEP8에서 self를 쓰는 것을 추천한다.
# __init__는 생성자로 인스턴스화 할 때 맞춰야하는 양식이다. 매개변수가 2개이므로 인자를 넣을 때 2개를 넣어야한다.
self.x = x
def __repr__(self):
return f'<Summing({self.x})>' #
def __add__(self, other):
print(f'{self}+{other}')
return Hi(self.x + other)
Summing(5) + 10
# <Summing(5)>+10
# <Hi(15)>
class X:
def __call__(self):
print(1)
callable(X)
# True
s = X()
s()
# 1
class
# type(function 방식) = .__class__ (메소드 방식)
a.__class__
# __main__.A
클래스 메소드/ 클래스 변수/ 인스턴스 메소드/ 인스턴스 변수
- dir(인스턴스): 인스턴스 변수, 클래스 변수, 인스턴스 메소드, 클래스 메소드 (모든게 다 나와야한다.)
- dir(클래스): 클래스 변수, 클래스 메소드, 인스턴스 메소드 + 클래스 관점에서 인스턴스 메소드는 function으로 관리하기 때문에 인스턴스 메소드를 볼 수 있는 것이다.
인스턴스 변수는 인스턴스 고유 기법이다. 따라서 클래스가 접근을 못한다.
vars(인스턴스): 인스턴스 변수의 값을 알려주는 것이다.
메소드 실행시킬 때마다 인스턴스 변수가 변환된다. 따라서 vars를 통해 인스턴스 변수만 확인할 수 있다.
class S:
def __init__(self):
self.a = 1
s = S()
set(dir(S))^set(dir(s))
# {'a'}
vars(s)
# {'a': 1}
# vars() == __dict__
s.__dict__
# {'a': 1}
# 따라서 __dict__가 정의 안되어 있으면 vars()를 못쓴다.
Class inheritance (상속)
class Door(type):
colour = 'brown'
def __init__(self, number, status):
self.number = number
self.status = status
@classmethod
def knock(cls):
print("Knock!")
@classmethod
def paint(cls, colour): # 클래스, 인스턴스 모두 사용 가능하고
cls.colour = colour # 클래스 변수 바꾼다
# 클래스로 접근한다 / 클래스만 값에 접근 가능
@classmethod
def paint2(cls, number): # number는 인스턴스 변수
cls.number = number # classmethod는 클래스 변수만 바꿀 수 있다
def open(self):
self.status = 'open'
def close(self):
self.status = 'closed'
class SecurityDoor(Door):
pass
Door.knock()
door = Door(1, 'open')
vars(door)
door.knock()
door.paint('red') # 인스턴스로 클래스 변수 바꿀 수 있음 (@classmethod)
door.colour
Door.colour
door.paint2(2)
door.number
Door.paint2(3) # 클래스만 인스턴스 변수 바꿀 수 있음 (@classmethod)
door.number
Door.number
'''
Knock!
{'number': 1, 'status': 'open'}
Knock!
'red'
'red'
1
1
3
'''
mappingproxy
클래스를 상속 받으면 원래 클래스 변수를 공유한다
※ 메모리 번지를 공유
sdoor = SecurityDoor(1, 'closed')
print(SecurityDoor.colour is Door.colour)
print(sdoor.colour is Door.colour)
:True
True
Composition (합성)
상속을 하지 않고 클래스 내에 객체(인스턴스)를 불러와 다른 클래스의 일부 기능을 사용하는 방법입니다. 컴포지션을 쓰면 좋은 이유는 인스턴스 변수가 상호작용하면서 메서드 하나로 다 작동됩니다. 따라서 관리(유지보수)하기가 좋습니다.
class SecurityDoor:
locked = True
def __init__(self, number, status):
self.door = Door(number, status) # Door의 객체를 갖게 한다
def open(self):
if self.locked:
return
self.door.open()
def __getattr__(self, attr): # try except와 비슷
return getattr(self.door, attr) # Door의 attr를 가져와라 (상속을 비슷하게 사용)
class ComposedDoor:
def __init__(self, number, status):
self.door = Door(number, status)
def __getattr__(self, attr): # 없으면 가져와라
return getattr(self.door, attr) # 바꾸지 않고 불러와서 사용할 때
class A:
x = 1
a = A()
hasattr(a,'x')
getattr(a,'x')
:True
1
2019년 11월 11일
Metaclass
메타클래스는 클래스의 클래스입니다. 메타클래스는 클래스 이름, 클래스 딕셔너리, 베이스 클래스와 같은 세 인자를 받아서 클래스를 만드는 책임을 집니다. 클래스가 메타클래스를 통해서 만들어졌기 때문에, 파이썬에서는 클래스가 객체입니다. 따라서 파이썬에 있는 모든것은 다 객체입니다. 대부분 객체 지향형 프로그래밍 언어들은 기본 구현을 제공합니다. 파이썬의 특별한 기능은 커스텀 메타클래스를 만들 수 있다는 것입니다. 메타클래스는 메모리 사용량을 줄이고, 모니터링하는데 중요한 기법입니다.
- Type
타입 또한 매타클래스입니다. 이는 클래스 행동을 지정할 수 있습니다. 예를 들어, 인스턴스를 한개만 만들 수 있도록 지정할 수 있습니다.
Singleton
항상 똑같은 인스턴스를 한개 밖에 못만드는 클래스입니다. 다음 코드를 확인해 본다면 있으면 type을 상속받은 것입니다. if문을 이용하여 기존에 있는 것 가져오도록 만들고, 없으면 새로운 것을 가져오도록 설정하였습니다.
class Singleton(type):
instance = None
def __call__(cls, *args, **kw): # 인스턴스에 ()(괄호) 붙일 수 있다.
if not cls.instance:
cls.instance = super(Singleton, cls).__call__(*args, **kw)
# super().__call__(*args, **kw) 동일
return cls.instance
class ASingleton(metaclass=Singleton):
pass
a = ASingleton() # __call__를 썼기에 괄호를 붙일 수 있다.
b = ASingleton()
a is b
# True
Object Reference 기법
이름이 똑같은 mutable 타입은 하나 바꾸면 같이 바뀐다. Mutable 데이터를 똑같은 이름으로 할당하거나, 클래스 변수는 조심해야한다. 클래스 변수도 Object reference 가 쓰입니다. 인스턴스 변수는 참조(reference) 안합니다.
class A:
x = 1
def __init__(self, a):
self.a = a
class B(A):
pass
b = B(2)
id(b.x) == id(A.x) == id(B.x)
# True
c = B(5)
id(c.a) == id(c.x) # 인스턴스 변수인 c.a는 참조하지 않는다.
# False
Mangling
맹글링은 소스 코드에서 선언된 함수 또는 변수의 이름을 컴파일 단계에서 컴파일러가 일정한 규칙을 가지고 변형하는 것을 말합니다. 이는 보통 객체 지향에서 오버로딩시 함수의 이름이 같고 파라미터만 다를때 알아서 구별할 수 있도록 하는데 사용됩니다.
# Mangling : 접근하면 안되므로 임시로 바꿔주는 것이다.
class T:
__t = 1
___t = 1
T._T__t
# 1
T._T___t
# 1
_ # 방금 전에 실행된 값을 실행해 준다. 하지만 쓰지 않는 것을 추천한다.
# 1
with 구문
- enter
- exit
이 두개가 정의되어 있으면 with 구문을 쓸 수 있습니다. 원래는 open과 close를 써서 파일을 불러올 수 있지만, with 구문으로 쓰면 자동으로 open과 동시에 with 구문이 끝날 때 __exit__가 실행되어 파일이 닫힙니다. 따라서 with 구문을 넘어가면 파일을 사용할 수 없습니다. open을 많이 안쓰는 이유는, 메모리를 차지하기 때문에 너무 많이 파일을 오픈하면 매번 close로 파일을 닫기보다 with를 사용하는 것이 더 효율적이기 때문입니다.
%%writefile cho.txt
Nice to meet you
하이
니하오
안녕
## with
with open('cho.txt', encoding = 'utf-8') as f:
next(f)
next(f)
print(f.read())
'''
니하오
안녕
'''
# with 안에 generator 테크닉인 next를 쓸 수 있다.
## open & close
a = open('cho.txt', encoding='utf-8')
a.read()
# 'Nice to meet you \n하이\n니하오\n안녕\n'
a.close() # 파일을 닫아준다.
언더바(_)의 총 7가지 방법
- _*
- from module import *에 의해 포함되지 않는 변수명명법
- %whos에 안보임
- *
- magic or special method 명명법
- __*
- mangling
- 클래스내에 __를 사용하여 변수명을 바꿔주는 방법
- 이때 외부에서 해당 변수에 접근을 하지 못하는 private 기능을 하는 것처럼 눈속임을 한다
- _
- 숫자에 쓰는 언더바
- ex) a = 100_000
- _ (이름이 중요하지 않지만 관례상 쓸때)
for i,_,k in zip([1,2,3],[4,5,6],[7,8,9]):
print(i,_,k)
for i,_,_ in zip([1,2,3],[4,5,6],[7,8,9]):
print(i,_,_)
- 주의, 맨 마지막에 쓴 값 출력 (할당하지 않으면)
- _method
- private
- _ 맨 마지막에 쓴 값 출력 (할당하지 않으면)
a = 3 a # 3 _ # 3
(8). _() # 다른 언어지원할 때
- 라이브러리 사용해야 해서 기본 7가지로 생각
무단 배포 금지
Comments